

Merhaba arkadaşlar,
Mobilhanem.com üzerinden anlattığımız/yayınladığımız Algoritma Eğitimleri serimize devam ediyoruz. Bu yazımızda sizlere dinamik programlamanın temellerini anlatmak üzere hazırladığımız En Uzun Ortak Alt Küme (Longest Common Subsequence) algoritmasında bahsedeceğiz.
Elimizde iki tane liste olduğunu varsayalım. Sayı veya Harflerden oluşsun hiç farketmez bu iki küme arasında sıralı bir şekilde en uzun ortak alt kümeyi nasıl buluruz.?
Aklınıza gelen ilk cevap listelerden birini referans alarak diğer listede, seçtiğimiz listedeki her bir elemanı tek tek aratmak olacaktır.
Basit bir örnek üzerinden kısaca açıklayalım.
Örnek
1. Liste: {A, B, T, C, D, E, F, G, Z}
2. Liste: {A, B, X, D, F, G, T}
Referans olarak 1.listeyi ele alalım. Bu kısımda tercih size kalmış isterseniz 2.listeyi de referans olarak alabilirdiniz değişen hiçbir şey olmayacaktır.
İlk olarak A (1. listenin ilk elemanı) 2.listede tüm elemanlar ile kıyaslanacaktır eğer var ise kaydedilecektir. Aynı şekilde 2. eleman içinde aynı şeyi yapacağız. (B) sürekli bu şekilde kıyaslama yaparak tüm listede sıralı ortak elemanları bulacağız.
Sonuç: [A, B, D, F, G] şeklinde olacaktır.
Java Kodu
for (int i=0; i<stringList2.size(); i++) {
for (int j=i; j<stringList.size(); j++) {
if (stringList2.get(i).equals(stringList.get(j))){
stringCommons.add(stringList.get(j));
}
}
}
System.out.println(stringCommons); // [A, B, D, F, G]
Bu problemde birden fazla sıralı alt küme bulabilirsiniz fakat hedefinizin en uzun ortak alt kümeyi bulmak olduğunu unutmayınız.
Buraya kadar herşey yolunda fakat yazının başında bu algoritmanın dinamik programlama temelli bir algoritma olduğunu söylemiştik fakat şuana kadar yaptıklarımızda bunun izleri görünmüyor. Her bir elemanı tek tek dolaştık ve kıyaslama yaparak sonuca ulaştık fakat dinamik programlama yaklaşımını göz önüne alırsanız eğer bu problemi daha kısa bir zamanda çözmemizin mümkün olacağını anlarsınız.
Gelin bir de bu problemi şu şekilde çözelim.
Aşağıda verilen tablo örneğimizdeki değerler referans alınarak verilmiştir.
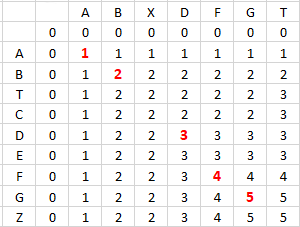
Bu tabloyu yorumlayacak olursak sağ alt köşede ki değer bizim bulacağımız en uzun ortak alt kümenin uzunluğudur. Gerçektende cevaba bakacak olursak [A, B, D, F, G] 5 elemanlı olduğu doğrulanacaktır.
Gördüğünüz üzere 1. listeyi satrılara 2. listeyi ise sütunlara dizdik yanlarına birer satur ve sutün 0 lar ile doldurduk. Her satır ve sütunda aynı elemana karşılık gelen değerlerin değerini 1 arttırmış olduk. Yani 7.satır 6.sütuna baktığımız zaman D harflerinin kesiştiğini göreceksiniz. Adım adım bu şekilde devam ettiğimiz zaman sağ alt köşeye doğru gidildiğini ve en son bulunan değerin ise cevabın yani en uzun ortak alt kümenin eleman sayısını (uzunluğunu) verdiğini göreceksiniz.
Peki tablodaki diğer değerler neye göre dolduruluyor. ?
Her eleman kontrol edilirken solundaki ve üzerinde eleman referans alarak değerlendirilir. Örneğin 4.satır(B) ve 3.sütun(A) da bulunan 1 rakamı üzerindeki ve solundaki rakama bakılarak en büyüğü hangisi ise o yazılarak seçilmiştir. Çünkü A ve B harfleri aynı harfler değil dolayısıyla ortak eleman değil. Fakat 4.satır(B) ve 4.sütun(B) da bulunan 2 rakamı sol üst tarafta bulunan 1 rakamının 1 fazlası olarak ifade edilir. Ortak eleman ve ortak olmayan elemanların değerlendirilmesi bu şekildedir.
Dinamik programlama yaklaşımında kesiştiği noktaları göz önüne alarak diğer durumları değerlendirmeye katmaz isek daha kısa zamanda algoritmayı tamamlamış olacağız. Tabloda bulunan kırmızı renkli rakamlar satır ve sütun bazında ortak elemanları ifade etmektedir.
Java Kodu
int computeLCS(char[] seq1, char[] seq2) {
int N = seq1.length;
int M = seq2.length;
int[][] lcs_table = new int[N + 1][M + 1];
for (int i = 0; i <= N; i++) {
for (int j = 0; j <= M; j++) {
if (i == 0 || j == 0)
lcs_table[i][j] = 0;
else if (seq1[i-1] == seq2[j-1])
lcs_table[i][j] = 1 + lcs_table[i - 1][j - 1];
else
lcs_table[i][j] = Math.max(lcs_table[i - 1][j], lcs_table[i][j - 1]);
}
}
return lcs_table[N][M];
}
Daha fazla ayrıntı için buradan faydalanabilirsiniz.
Umarım faydalı bir algoritma olmuştur.
Hoşçakalın.
3